A brief overview of the selected research problems tackled by the Signal Processing Group are given below.
Speaker recognition and diarization
The goal of the speaker recognition is to answer the question: “who is speaking”? It can be divided into two similar tasks: speaker verification or speaker identification. The first one returns the binary response, whether the speaker is who he/she claims to be or not. The latter is responsible for pointing out specific speaker from a group of people. Another task in speech processing is speaker diarization. It answers the question “who speaks when”, not necessarily by indicating a specific speaker. Both fields are recently deeply investigated, as their usage covers wide range of applications such as conference systems, virtual assistants, and biometric verification devices. Growing popularity of aforementioned applications puts high requirements for system effectiveness in terms of either security as well as user experience.
We tackle these problems using deep learning techniques. In our work, we focus on developing methods for modeling speaker embeddings with the deep neural networks (DNNs), which is currently state-of-the-art in this field. The members of the Signal Processing Group have proposed novel deep neural network architectures for modelling speaker embeddings with great accuracy. Furthermore, modifications to the loss function have been proposed with automatically adapting parameters of the cross-entropy loss, which further improved the efficacy of training and speaker inference. The general structure of the speaker recognition system can be presented as in diagram below:

It consists of extraction acoustic features, creation speaker model, estimating the similarity between two models and model calibration. One of the challenges in the speaker recognition domain is a speech recorded in real conditions where the utterance is distorted by other external distractors. Our approach enables to model speaker characteristics that are robust against adverse conditions such as environmental noise, background music or babble speech. Our research includes also far-field speaker recognition with dereverberation methods incorporated as a pre-processing step to the speaker recognition system.
Sound source separation
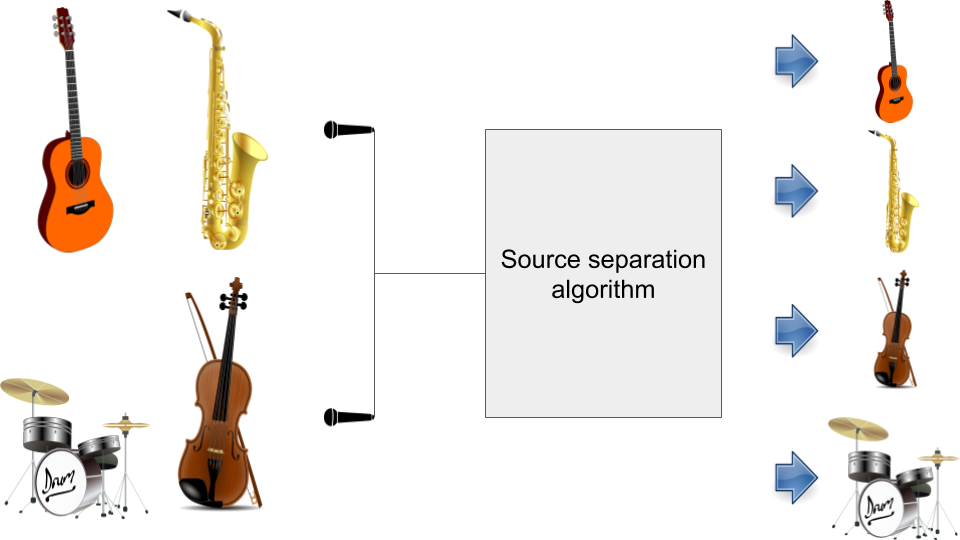
Sound source separation refers to the problem of extracting the signals of individual sound sources from the microphone mixture. It is often performed in the so-called blind scenario, in which separation is carried with limited or no additional information about the sources or the mixing process. The main applications of sound source separation include the recovery of individual recordings of instruments from a professionally mixed music piece and the isolation of speech of individual speakers from the microphone recordings in the so-called cocktail party scenario with multiple simultaneously active speakers. An example of an under-determined scenario in which we aim to extract the signals of four musical instruments from two microphone recordings is shown.
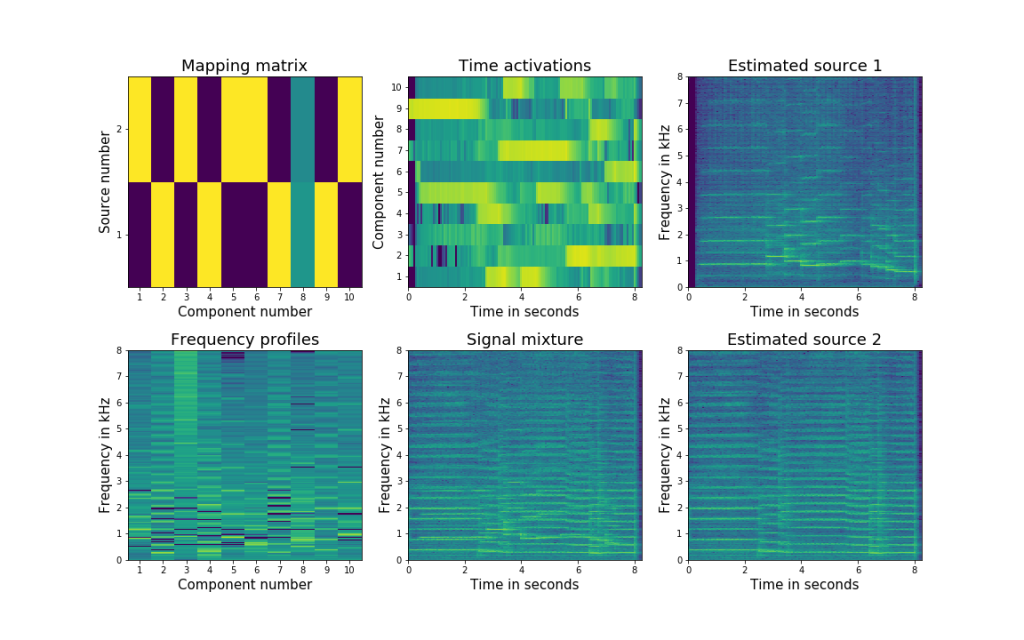
In principle, separation may be carried out using beamforming, independent component analysis (ICA), non-negative matrix factorization (NMF), nonnegative tensor factorization (NTF), and deep neural networks (DNN). In the Signal Processing Group, the research is focused primarily on the latter two approaches popular in audio processing and machine learning. NTF is an unsupervised data decomposition technique which consists in factorization of non-negative matrices with power spectra of an audio mixture into a sum of non-negative matrices representing source frequency profiles, time activations and a mapping matrix. This method is widely used for source separation because of the ease of exploiting the pre-trained frequency profiles of the sources and incorporation of various types of priors on the harmonic structure of the sources, smoothness of the respective factorized matrices, and the localization prior. In particular, we have extended the so-called sub-source EM algorithm based on the multiplicative update (MU) rules by incorporating smoothness on the factorized matrices and including the localization prior. Current research efforts include the DNN-based separation with application to separating musical instruments from audio channels and extracting individual speech signals from the microphone recordings in the cocktail party scenarios. Spectograms and non-negative matrices after decomposition are provided as an example.
Speech enhancement & noise suppression
The development of efficient noise-robust systems remains a challenge in the voice communication. Therefore, addressing the problem of high quality speech extraction, particularly difficult to approach in terms of adverse conditions such as low SNR scenarios and non-stationary environments, is of great importance and can significantly improve the performance of, for instance, automatic speech recognition (ASR) systems, whose accuracy is strongly affected by the presence of background noise. Furthermore, recent rapid increase in the number of smart devices equipped with acoustic sensors and advances in the newest IT technologies such as 5G and IoT enable design of reliable noise reduction algorithms for distributed setups. An example scenario with speech and noise detectors, and noisy and denoised microphone signals are given in the figure below.
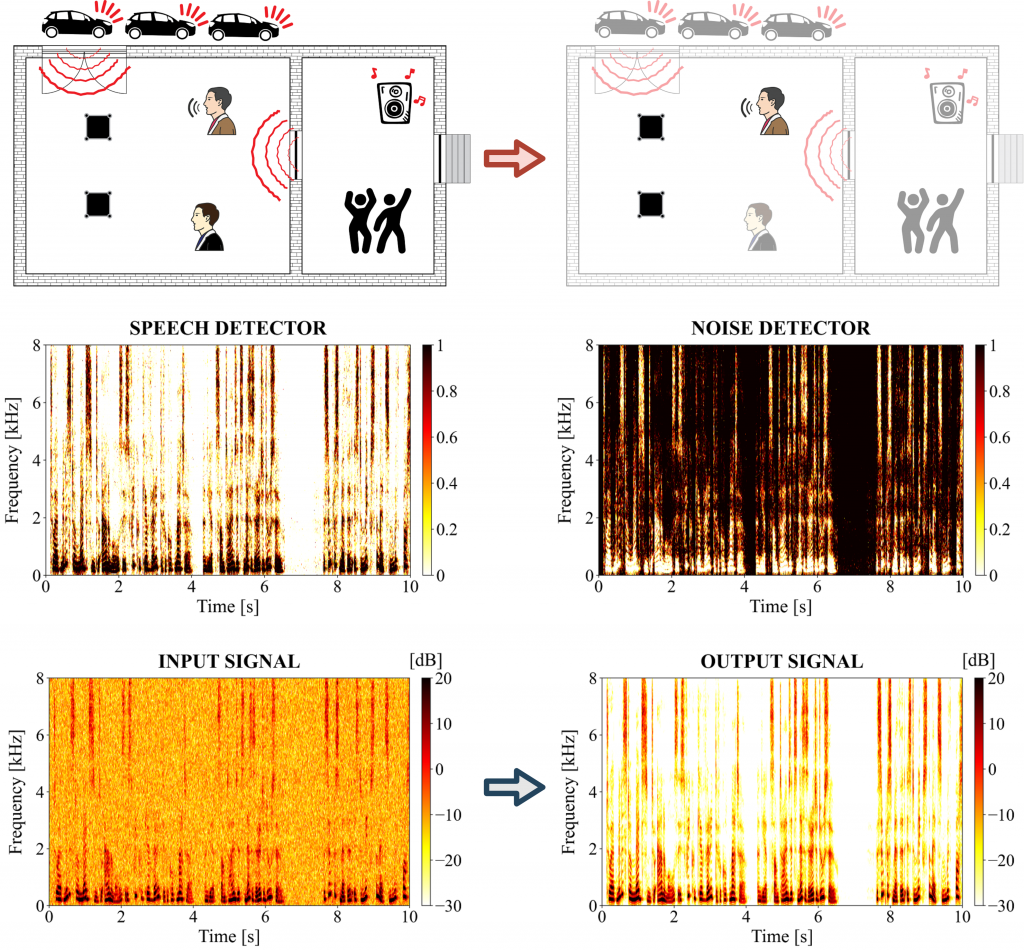
Enhancement of the speech corrupted by background noise can be performed in multiple ways. Our research efforts are focused on developing online multi-channel processing techniques which enable real-time operation and exploit both spectral and spatial properties of audio signals. The overall aim is to properly perform spatial filtering of noisy observations using estimated second order statistics of desired source signal and unwanted noise component. In our case, estimation of required statistics is based on so-called time-frequency masks which determine probability of speech being present or absent in considered time-frequency bin of multi-channel recordings and therefore act as a speech/noise detectors. We conduct analyses of both classical and novel approaches to masks estimation. The first ones concern statistical model-based methods which firstly assume a mathematical model of the microphone signals, sources or speech, including broadly known generative Gaussian mixture or hidden Markov models, and then introduce estimator such as maximum likelihood or maximum a posteriori in order to derive model parameters. Consistently with current trends we also develop novel approaches based on utilization of artificial neural networks and particularly deep learning techniques.
Localization
Maximum Likelihood (ML) acoustic source localization in spherical harmonic domain
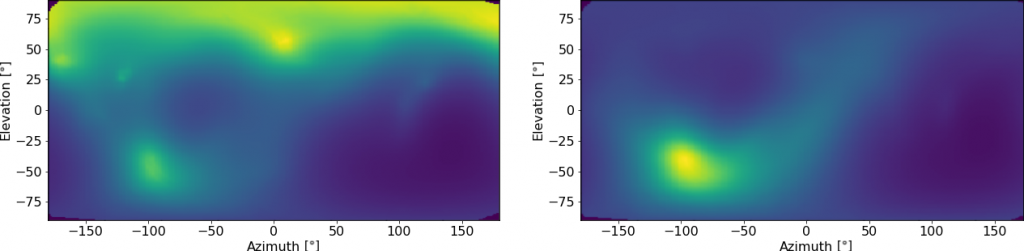
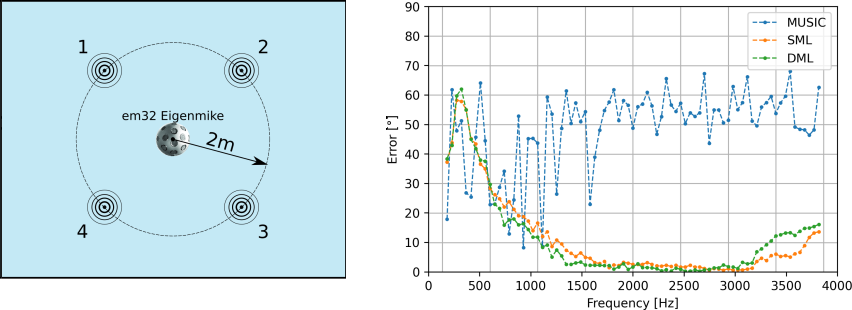
Direction of arrival (DoA) of a source is one of fundamental parameters of a multichannel audio recording and is commonly utilized both as a end result or as an input for further signal processing. When using circular or spherical microphone arrays, a change of the signal domain to e.g. the spherical harmonics domain may offer some advantages. Separation of frequency-dependent and angular-dependent components in the signal model provides a straightforward manner to expand classical narrowband localization algorithms such as MUltiple SIgnal Classification (MUSIC) to the broadband case. In the group, we develop novel in the field of audio DoA estimation methods, such as Stochasic Maximum Likelihood (SML) or Deterministic Maximum Likelihood (DML). Their application has been shown to improve the localization accuracy, increase the robustness in case of difficult acoustic conditions with reverberation and noise, and contrary to most standard algorithms enables the localization in case of correlated source signals. The following picture presents an example experimental setup consisting of a spherical microphone array that records 4 sources emitting correlated signals and the average angular localization error as a function of frequency for MUSIC, SML and DML.
Sound source localization based on multichannel audio recorded with microphone array integrated with a Micro Aerial Vehicle (MAV)
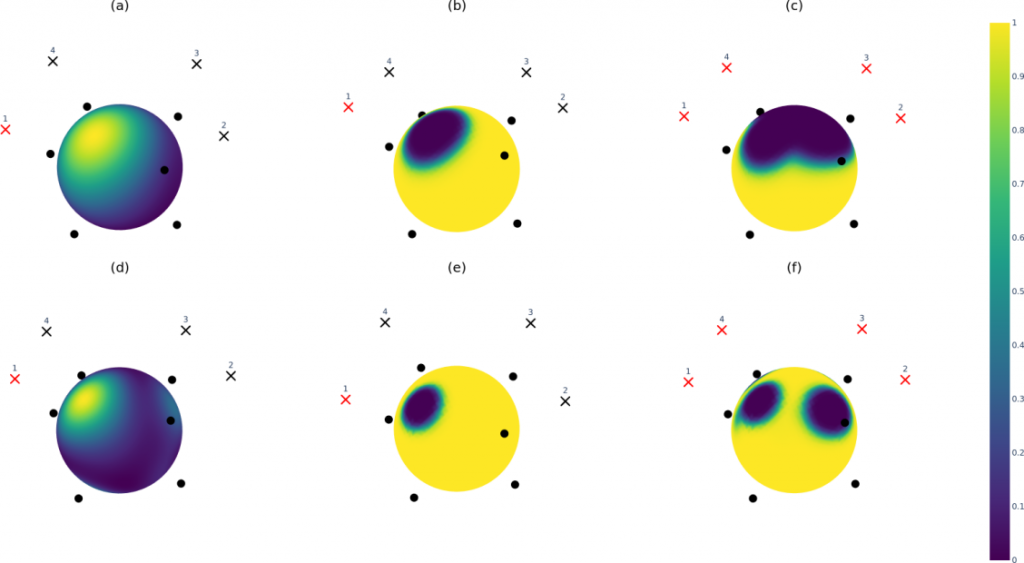
Acoustic sensing scenarios including microphone array mounted under a Micro Aerial Vehicle, commonly referred to as a drone, are an emerging signal processing challenge and as they gain importance they are becoming widely considered, for example during search and rescue operations. To overcome the heavy noise conditions encountered within the aforementioned localization setup, which are the result MAV’s propulsion system in close proximity of and the microphone array, several solutions have been developed. The first development is referred to as Spatio-Spectral Masking (SSM) and it aims to estimate a set of frequency-dependent masks that are applied to the angular pseudo-spectra to lessen the parts corresponding to MAV’s ego-noise. The SSM is based on Principal Component Analysis (PCA) of the angular pseudo-spectra computed for noise-only recordings database. The picture below presents example SSM masks: subfigure (a,d) presents principal components obtained for the first rotor, subfigure (b,e) shows SSM masks for the first rotors, and subfigure (c,f) shows the final merged SSM masks. The upper row(a-c) and the bottom row (d-f) present the results for 1200Hz 2000Hz, respectively. Crosses represent position of the rotors, while red cross denotes active rotor and black cross denotes an inactive rotor. Black dots represent positions of the microphones inside the array.
The second development referred to as Time-Frequency Masking (TFM) is a method that allows to detect which time-frequency bins carry most useful information about the source location, thus allowing the exclusion of the ego-noise contaminated narrowband angular pseudo-spectra. An example of ideal and estimated masks is shown in the picture.
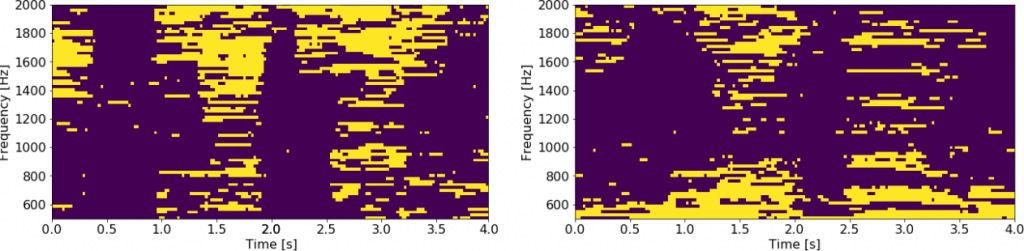
The last picture presents an example of a broadband spatial pseudo-spectrum without and with the application of TFM. The evaluation shows that joint application of both masking techniques significantly improves the localization accuracy, actually enabling to the successful localization.