
Project title: Audio Processing using Distributed Acoustic Sensors (APDAS)
Project type: Research project
Funding: First TEAM Program, Foundation for Polish Science (FNP)
Duration: 2018 – 2023
Project team members:
dr hab. inż. Konrad Kowalczyk, prof. AGH – principal investigator
dr inż. Stanisław Kacprzak – postdoctoral researcher
mgr inż. Marcin Witkowski – PhD student
mgr inż. Szymon Woźniak – PhD student
mgr inż. Magdalena Rybicka – PhD student
mgr inż. Julitta Bartolewska – PhD student member
mgr inż. Mieszko Fraś – PhD student member
mgr inż. Mateusz Guzik – student member
inż. Jan Wilczek – student member
Motivation
Recent developments of Internet Technologies (IT) have caused a rapid increase in numbers of smart devices in our surroundings, many of which are equipped with one or more microphones. Connecting several smart devices, known as the Internet of Things (IoT), has a great potential in overcoming the challenges of hands-free voice communication from distance such as a weak signal of a desired speaker, room reverberation, and high levels of background noise and interfering sounds.
Main project goal
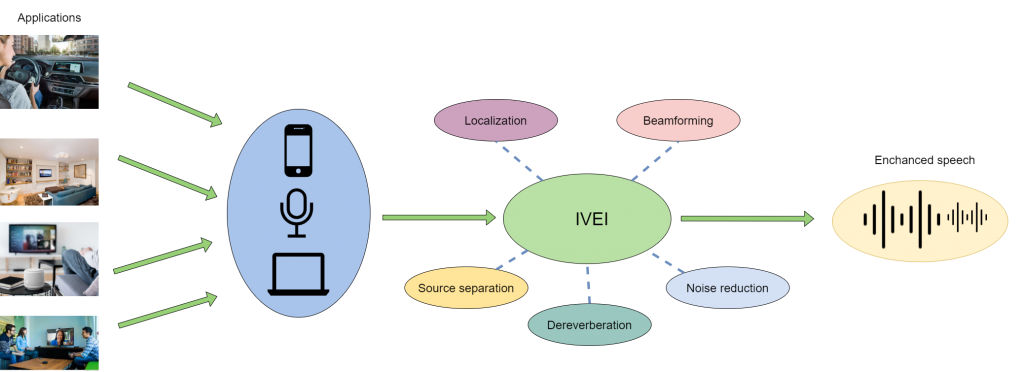
The main aim of this research project is to improve speech intelligibility in hands-free communication and provide robust voice-based human-computer interfaces from distance. Project team develops distributed audio signal processing techniques, which analyze the recorded sound scene, localize and identify acoustic sources, and extract and enhance signals of the desired speakers.
Applications
The developed solutions for distributed audio processing can be applied in various applications such as hands-free voice communication, teleconference systems, diarization and transcription of office meetings, capturing voice commands to control “smart” home and building appliances, and interaction with virtual assistants from distance using distributed “smart” speakers.
Major research achievements
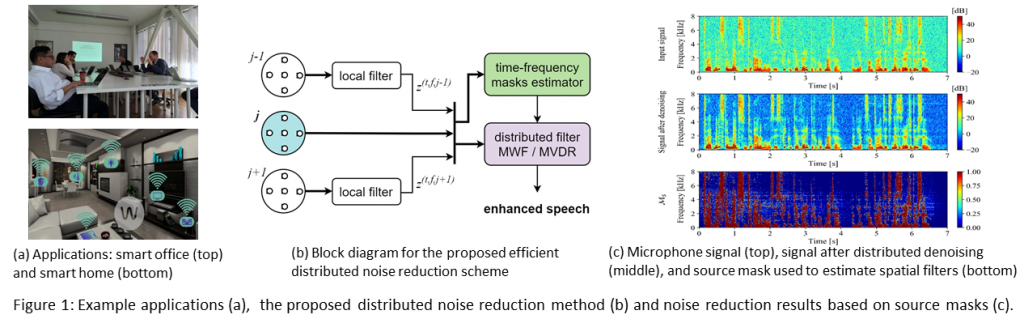
– Proposal of an efficient algorithm for distributed multi-array noise reduction, with online estimation of noise statistics, time-frequency masks and spatial filters, based on exchanging a limited number of audio signals.
– Proposal of a multichannel linear-prediction based dereverberation algorithm based on split Bregman approach, which enables speech sparsity control to achieve improved dereverberation performance.
– Development of a speaker model based on embeddings from deep neural networks (DNNs) for improved speaker recognition from (i) short speech segments and (ii) recordings of microphones distributed in a room.
– Proposal of a multichannel source separation scheme based on non-negative tensor factorization (NTF) with incorporated spatial information gathered by the distributed microphones – joint source and location model
– Proposal of a joint two-step maximum likelihood method for self-localization of distributed microphone arrays and synchronization of timeline offsets between the clocks of distributed devices with robustness towards (i) the measurement errors and (ii) random initializations.
Intelligent Voice Enhancement Interface (IVEI)
One of golas of the project is to integrate independently developed solutions into a joint distributed voice enhancement interface, to implement a software library with the developed functionalities for technology evaluation and commercialization purposes, and to verify and optimize its performance in practical application scenarios. Project outcome includes an Intelligent Voice Enhancement Interface (IVEI) software library for distributed / multichannel front-end processing.
International project partners
University of Valencia, Spain
Katholieke Universiteit Leuven, Belgium
Johns Hopkins University, USA
Publications
[J3] M. Fraś and K. Kowalczyk, “Convolutional Weighted Parametric Multichannel Wiener Filter for Reverberant Source Separation,” in IEEE Signal Processing Letters, vol. 29, 2022, doi: 10.1109/LSP.2022.3203665.
[J2] M. Witkowski and K. Kowalczyk, “Split Bregman Approach to Linear Prediction Based Dereverberation With Enforced Speech Sparsity,” in IEEE Signal Processing Letters, vol. 28, pp. 942-946, 2021, doi: 10.1109/LSP.2021.3070734.
[J1] S. Woźniak and K. Kowalczyk, “Passive Joint Localization and Synchronization of Distributed Microphone Arrays,” in IEEE Signal Processing Letters, vol. 26, no. 2, pp. 292-296, Feb. 2019, doi: 10.1109/LSP.2018.2889438.
[C10] Stanisław Kacprzak, Magdalena Rybicka, and Konrad Kowalczyk, “Spoken Language Recognition with Cluster-based Modeling,” 2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 2022, pp. 6867-6871, doi: 10.1109/ICASSP43922.2022.9747515.
[C9] J. Bartolewska and K. Kowalczyk, “Frame-based Maximum a Posteriori Estimation of Second-Order Statistics for Multichannel Speech Enhancement in Presence of Noise,” IEEE Int. Work. Multimedia Signal Processing, Tampere, Finland, 2021, pp. 1-6, doi: 10.1109/MMSP53017.2021.9733520.
[C8] M. Fraś, M. Witkowski and Kowalczyk, “Combating Reverberation in NTF-Based Speech Separation Using a Sub-Source Weighted Multichannel Wiener Filter and Linear Prediction,” Annual Conf. Int. Speech Communication Association (Interspeech), Brno, Czech Republic, pp. 3895-3899, doi: 10.21437/Interspeech.2021-1230.
[C7] M. Rybicka, J. Villalba, P. Żelasko, N. Dehak and Kowalczyk, “Spine2Net: SpineNet with Res2Net and Time-Squeeze-and-Excitation Blocks for Speaker Recognition,” Annual Conf. Int. Speech Communication Association (Interspeech), Brno, Czech Republic, pp. 496-500, doi: 10.21437/Interspeech.2021-1163.
[C6] M. Fraś and K. Kowalczyk, “Maximum a posteriori estimator for convolutive sound source separation with sub-source based NTF model and the localization probabilistic prior on the mixing matrix,” 2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Vancouver, Canada, 2021, pp. 526-530, doi: 10.1109/ICASSP39728.2021.9413863.
[C5] M. Rybicka and K. Kowalczyk, “On Parameter Adaptation in Softmax-based Cross-Entropy Loss for Improved Convergence Speed and Accuracy in DNN-based Speaker Recognition,” Annual Conf. Int. Speech Communication Association (INTERSPEECH), Shanghai, China, 2020, pp. 3805-3809, doi: 10.21437/Interspeech.2020-2264.
[C4] J. Bartolewska and K. Kowalczyk, “Distributed Multiarray Noise Reduction With Online Estimation Of Masks And Spatial Filters,” 2020 IEEE 11th Sensor Array and Multichannel Signal Processing Workshop (SAM), Hangzhou, China, 2020, pp. 1-5, doi: 10.1109/SAM48682.2020.9104400.
[C3] S. Woźniak and K. Kowalczyk, “Exploiting Rays in Blind Localization of Distributed Sensor Arrays,” ICASSP 2020 – 2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 2020, pp. 221-225, doi: 10.1109/ICASSP40776.2020.9054752.
[C2] M. Witkowski, M. Rybicka and K. Kowalczyk, “Speaker Recognition from Distance Using X-Vectors with Reverberation-Robust Features,” 2019 IEEE Int. Conf. Signal Processing: Algorithms, Architectures, Arrangements, and Applications (SPA), Poznan, Poland, 2019, pp. 235-240, doi: 10.23919/SPA.2019.8936665.
[C1] S. Woźniak, K. Kowalczyk and M. Cobos, “Self-Localization of Distributed Microphone Arrays Using Directional Statistics with DoA Estimation Reliability,” 2019 27th European Signal Processing Conference (EUSIPCO), A Coruna, Spain, 2019, pp. 1-5, doi: 10.23919/EUSIPCO.2019.8902788.